There’s a new entry in your server logs almost every week. Another AI bot, crawling your site. It’s the visible edge of a much bigger shift in how the internet works. Half the SEO blogs in your inbox will tell you to block them all.
Most of the time, you shouldn’t.
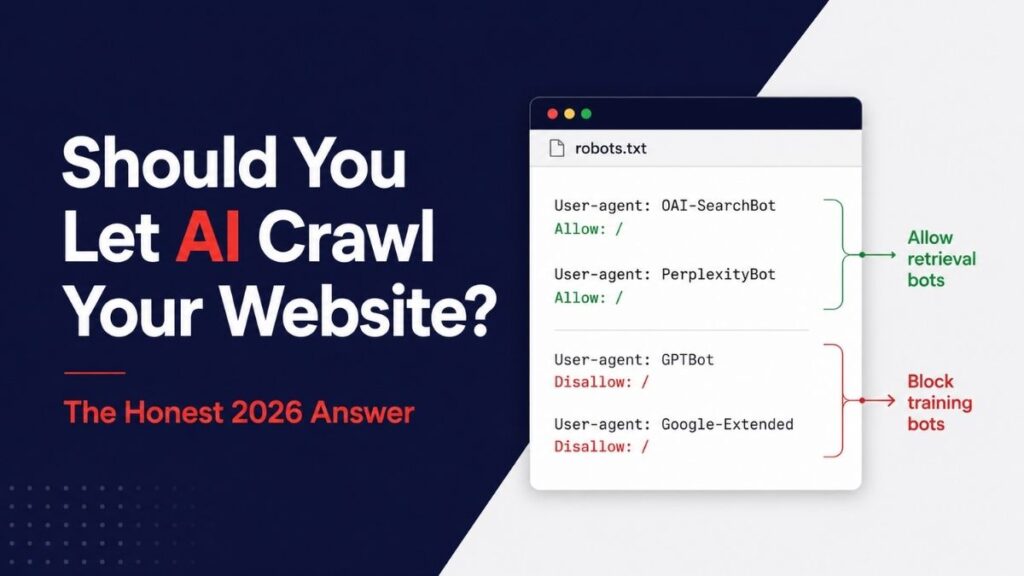
The short version: Let the retrieval bots (ChatGPT, Perplexity, Claude) in. Block the training bots (GPTBot, Google-Extended, CCBot) only if you want to. The robots.txt to copy is further down.
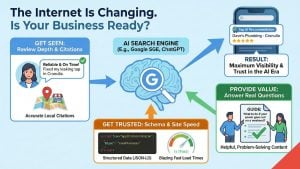
So, should you let AI crawl your website? Here’s what’s actually crawling, why the answer is different for the bot that wants to train its model and the bot that wants to cite you, and what most Sydney businesses should actually do.
Bot names and behaviour in this post are current as of May 2026. This space moves fast. We update when it shifts.
There are two kinds of AI crawler, and treating them the same is the mistake most articles are making.
Training crawlers scrape your content to feed model training. They include OpenAI’s GPTBot, Google’s Google-Extended (which is separate from Googlebot), Anthropic’s ClaudeBot, and CCBot from Common Crawl, which feeds dozens of downstream models. They take from your site. They don’t send anyone back.
Retrieval crawlers fetch your content live when an AI product needs to answer a question or cite a source. These include OAI-SearchBot (ChatGPT search), PerplexityBot, Claude-SearchBot, and user-triggered fetchers like Perplexity-User. When these bots crawl you, your business has a chance of showing up as a citation in an AI answer.
That’s the difference.
The first kind takes. The second kind cites. Treating them the same is how you end up invisible to ChatGPT for no good reason.
If you want to ensure your Sydney business is AI-ready moving forward, you should allow retrieval crawlers to cite you. That way, you will be discoverable in local searches.

Should you let AI crawl your website? The honest 2026 picture
Reddit blocks GPTBot. The New York Times blocks it. Most major publishers block it. They have content libraries worth protecting and lawyers paid to protect them.
Most Sydney small businesses are not in that position. The model isn’t being meaningfully trained on your services page. The honest case for blocking the training bots, for a small business, is mostly philosophical: “I don’t want to help OpenAI build the next product when they’re not paying me.” Fair. Just understand that’s the argument, not a technical or strategic one.
The case for blocking the retrieval bots is much weaker. Those bots are how your business shows up in AI answers. Blocking OAI-SearchBot is the 2026 equivalent of blocking Googlebot in 2010. You don’t appear in the answer. You don’t get the citation. You don’t get the click.
The traffic from AI citations is small today. The share is climbing every quarter. The compounding starts now.
Ensure you position yourself for future disruption.
What your Sydney business should actually do
We get asked about this every week now. The honest answer is the same one we give for most new search trends: it depends on what you sell.
Let the retrieval bots in if:
- You publish content like a blog, guides, or case studies that earn search traffic
- You sell a considered service that people research before buying
- Your customers are starting to ask ChatGPT or Perplexity for recommendations before they Google
You can safely block the training bots if:
- You publish original analysis, research, or paid content you’d rather not see scraped for free
- The “I’m not subsidising someone else’s model” argument matters to you on principle
- You’re already overdue on more important SEO basics, in which case do those first
Even if you’re a purely local business, let the retrieval bots in. It costs nothing, and “best coffee in Surry Hills” is increasingly a ChatGPT query, not just a Maps query. The only way to be in that answer is to be readable when the bot fetches.
The rule of thumb: let retrieval in, block training if it helps you sleep, and spend more time on being worth citing than on managing who gets to see you.
How to allow or block AI crawlers in robots.txt
Three steps.
- Open your
robots.txtfile. It lives atyoursite.com/robots.txt. On WordPress, Yoast and Rank Math both let you edit it from the admin. Otherwise, edit it via your host’s file manager. - Add the rules you want. A balanced setup looks like this:
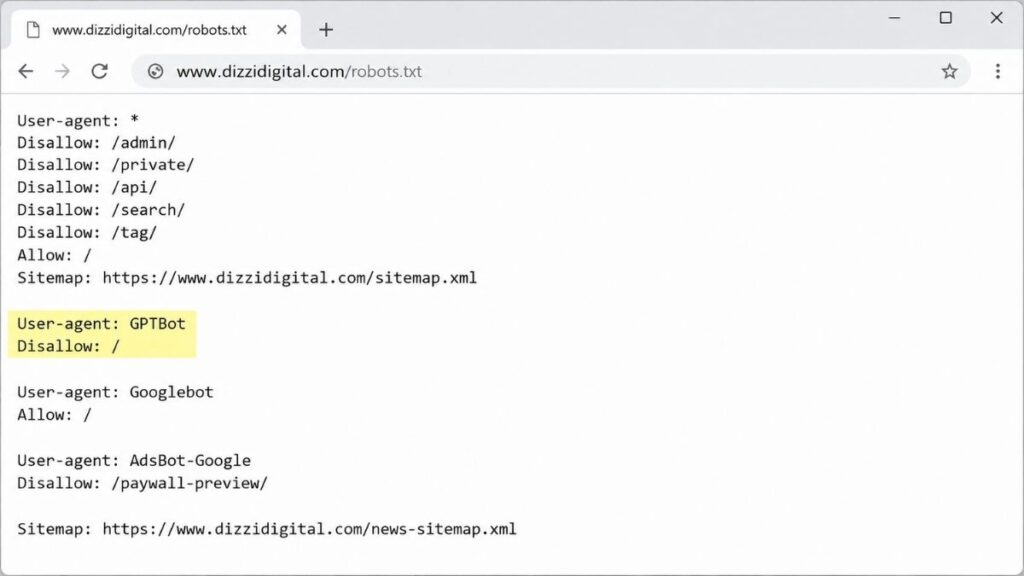
# Block training scrapers
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
# Allow retrieval bots
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: ClaudeBot
Allow: /
- Test it. Visit
yoursite.com/robots.txtto confirm it loads. Most reputable AI bots respect what’s there. The shady ones don’t, and there’s norobots.txtrule that fixes that.
Once your robots.txt is sorted, the next layer is llms.txt, a separate file that tells AI tools how to read your site once you’ve let them in. We covered the setup in our guide to llms.txt for Sydney businesses.
FAQ
Will blocking AI bots hurt my Google rankings?
No. Googlebot and Google-Extended are separate crawlers. Blocking Google-Extended stops your content being used to train Gemini. It does not affect your ranking in Google Search. Google has confirmed this publicly.
Do AI bots actually respect robots.txt?
Most named ones do. GPTBot, ClaudeBot, PerplexityBot, Google-Extended, and CCBot all honour standard robots.txt rules. Unknown scrapers and unnamed bots are a different story, and there’s no clean fix for that at the file level. Treat robots.txt as a clear statement of intent, not a wall.
Should I block Google-Extended specifically?
Tradeoff. Blocking it stops your content training Gemini and Vertex AI. It does not stop you appearing in Google’s AI Overviews, which use a different signal. If training Gemini bothers you, block it. If not, leave it.
What is the difference between GPTBot and OAI-SearchBot?
Both belong to OpenAI but do different jobs. GPTBot is a training crawler. It scrapes your content to feed future ChatGPT models. OAI-SearchBot is a retrieval crawler. It fetches your pages live when a ChatGPT user runs a search and the model needs to cite a source. Block GPTBot if you’d rather not contribute to training. Allow OAI-SearchBot if you want to appear in ChatGPT’s search answers.
Will this stop my content being used to train AI?
Only for the bots that respect robots.txt. Plenty of training data is scraped through third-party datasets, archived snapshots, and unnamed crawlers you can’t block. If your content is on the public internet, assume some version of it is already in a training set somewhere.
The bottom line
So, should you let AI crawl your website? For most Sydney small businesses, the right answer is to let the retrieval bots through and block the training scrapers if you want to. Either way, the decision matters less than just being readable to AI in the first place.
The bigger risk in 2026 isn’t that someone trains a model on your homepage. It’s that no AI product can find you when a customer asks for a recommendation.
Want more honest takes on AI search and what’s actually working for small businesses?
Sign up for the Dizzi Digital newsletter. One email a month. Practical, no-fluff coverage of AI search, web design, and how the internet is actually changing for operators who ship.